🔥Hot News: Сегодня мы добавили на Арену сразу ДВА бенчмарка
Встречайте PingPong Benchmark и Simple-Evals-RU — новые инструменты для оценки языковых моделей.
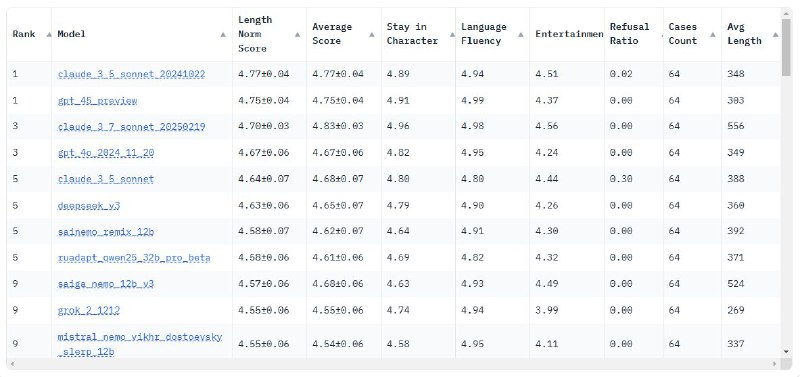
➡️PingPong Benchmarkтестирует модели в ролевых диалогах. Здесь LLM-ки не только генерируют ответы, но и выступают в роли пользователей. Набор персонажей и ситуаций проверяет способность модели сохранять выбранную роль в многораундовой беседе.
Оценка идет по трем критериям: - Соответствие персонажу — насколько точно модель играет свою роль. - Развлекательность — насколько интересны её ответы. - Языковая грамотность — естественность и корректность речи.
Результат — усредненный рейтинг по всем параметрам.
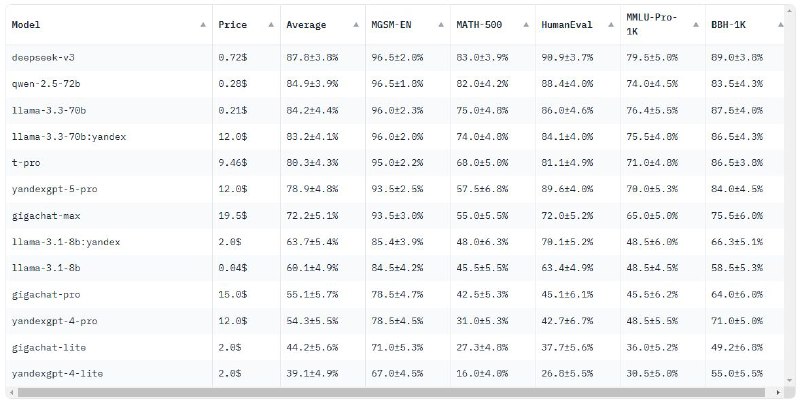
➡️Simple-Evals-RU— это бенчмарк, который проверяет модели на математических, логических и программных задачах. Он включает тесты MGSM, MATH, HumanEval, MMLU-Pro и BBH, а также сравнивает стоимость работы моделей на миллион токенов.
Методология основана на simple-evals от OpenAI, поддерживает только Instruction-модели и использует Zero-shot и Chain-of-Thought промпты.
Оба бенчмарка уже доступны на платформе, найти их можно на сайте llmarena.ru➡️ во вкладке «Таблица лидеров» ➡️ «PingPong» и «Simple-Evals».
Какие бенчмарки вам ещё интересны? Пишите в комментариях 👇
🔥Hot News: Сегодня мы добавили на Арену сразу ДВА бенчмарка
Встречайте PingPong Benchmark и Simple-Evals-RU — новые инструменты для оценки языковых моделей.
➡️PingPong Benchmarkтестирует модели в ролевых диалогах. Здесь LLM-ки не только генерируют ответы, но и выступают в роли пользователей. Набор персонажей и ситуаций проверяет способность модели сохранять выбранную роль в многораундовой беседе.
Оценка идет по трем критериям: - Соответствие персонажу — насколько точно модель играет свою роль. - Развлекательность — насколько интересны её ответы. - Языковая грамотность — естественность и корректность речи.
Результат — усредненный рейтинг по всем параметрам.
➡️Simple-Evals-RU— это бенчмарк, который проверяет модели на математических, логических и программных задачах. Он включает тесты MGSM, MATH, HumanEval, MMLU-Pro и BBH, а также сравнивает стоимость работы моделей на миллион токенов.
Методология основана на simple-evals от OpenAI, поддерживает только Instruction-модели и использует Zero-shot и Chain-of-Thought промпты.
Оба бенчмарка уже доступны на платформе, найти их можно на сайте llmarena.ru➡️ во вкладке «Таблица лидеров» ➡️ «PingPong» и «Simple-Evals».
Какие бенчмарки вам ещё интересны? Пишите в комментариях 👇
Among the actives, Ascendas REIT sank 0.64 percent, while CapitaLand Integrated Commercial Trust plummeted 1.42 percent, City Developments plunged 1.12 percent, Dairy Farm International tumbled 0.86 percent, DBS Group skidded 0.68 percent, Genting Singapore retreated 0.67 percent, Hongkong Land climbed 1.30 percent, Mapletree Commercial Trust lost 0.47 percent, Mapletree Logistics Trust tanked 0.95 percent, Oversea-Chinese Banking Corporation dropped 0.61 percent, SATS rose 0.24 percent, SembCorp Industries shed 0.54 percent, Singapore Airlines surrendered 0.79 percent, Singapore Exchange slid 0.30 percent, Singapore Press Holdings declined 1.03 percent, Singapore Technologies Engineering dipped 0.26 percent, SingTel advanced 0.81 percent, United Overseas Bank fell 0.39 percent, Wilmar International eased 0.24 percent, Yangzijiang Shipbuilding jumped 1.42 percent and Keppel Corp, Thai Beverage, CapitaLand and Comfort DelGro were unchanged.
The S&P 500 slumped 1.8% on Monday and Tuesday, thanks to China Evergrande, the Chinese property company that looks like it is ready to default on its more-than $300 billion in debt. Cries of the next Lehman Brothers—or maybe the next Silverado?—echoed through the canyons of Wall Street as investors prepared for the worst.